

When evaluating an AI product for knowledge work, fluency is a reasonable bar. For technical sales, it is the beginning of a failure mode. Let me explain.
A customer asks about alternatives to a material they're currently using. Sounds routine, but the answer has to hold across performance specs, process conditions, geography, and compliance. The rep runs the question through a general AI tool, gets back something clean and confident, and passes it along internally because it reads like a real recommendation. Later, someone catches that the product was discontinued months ago, or that the recommendation skipped a regulatory constraint that should have ruled it out immediately. The answer was wrong, but nothing about it felt wrong.
Bad recommendations are worse than you think
A common problem we see when evaluating AI for sales in the chemical industry is starting with the wrong tests. Leaders look at whether the system sounds smart, writes cleanly, or can answer a question quickly in a way that feels complete. That is easy to overvalue because fluency is visible. It creates the impression that the hard part has already been solved.
In technical sales, the hard part is consistently producing answers that are trusted enough to influence a real decision. Customers are not shopping for a second opinion. They are mid-project, facing a constraint, and asking which product fits the requirement, which alternative is safe to propose, which option will actually perform under their process conditions, and which recommendation will still hold up when procurement, regulatory, and technical teams all look at it.
A polished wrong answer fails quietly. It gets passed around, repeated in internal threads, dropped into follow-up emails, and treated as though it carries more certainty than it actually does. In technical selling, that can kill a deal, create rework and slowdown, weaken trust, or push a team toward a recommendation that should never have been made.
Technical sales is recommendation under constraints
Technical selling gets flattened too often into generic sales enablement. Better emails, faster note-taking, cleaner follow-ups, easier search. Those tasks matter, and AI can help with many of them, but they are the edges of the workflow.
The core of the job is recommendation under constraints. A customer has a use case, a target outcome, and a set of conditions that narrow the decision space: performance requirements, compatibility, application conditions, geography, compliance, internal business rules. In many industries, especially scientific and industrial ones, navigating those constraints is the job. They are not implementation details that come after the real thinking is done.
That changes the standard for what AI needs to do here. A general-purpose assistant can be useful even when it is loose around the edges but technical sales cannot afford that. The answer has to be grounded, repeatable, and explainable enough that someone can put it into a live commercial process and stand behind it.
Where general models stop being enough
Tools like ChatGPT, Claude, and Copilot are good. We use some of them every day and encourage our customers to do the same. General products are already useful across commercial teams. They help summarize documents, draft customer communications, clean up internal notes, organize messy information, and help people orient themselves faster in unfamiliar territory.
They can also be helpful on more complex work, like framing technical questions, comparing concepts at a high level, or surfacing issues a rep should explore further. In many cases, they help a decent rep become faster and more prepared. That is real productivity and it deserves credit.
The issue starts when people confuse this usefulness with dependable recommendation. A system can be very helpful and still not be reliable enough for high-stakes technical selling. That distinction matters more in industries built on scientific data, because the underlying information environment is uneven. Public information is sparse, product visibility online is inconsistent, and what shows up is shaped more by SEO and marketing presence than by technical accuracy. That is a weak foundation for answering domain-specific commercial questions with confidence.
The issue is usually not the model
A lot of people frame this category as a model race. Which assistant is smarter, which vendor has the best AI, which competitor has the strongest model under the hood. In practice, that is often the wrong place to look. Most products in this category are built on top of the same small set of foundation models, including many that appear very different at the surface. The model itself is rarely the whole story, and often not the main one.
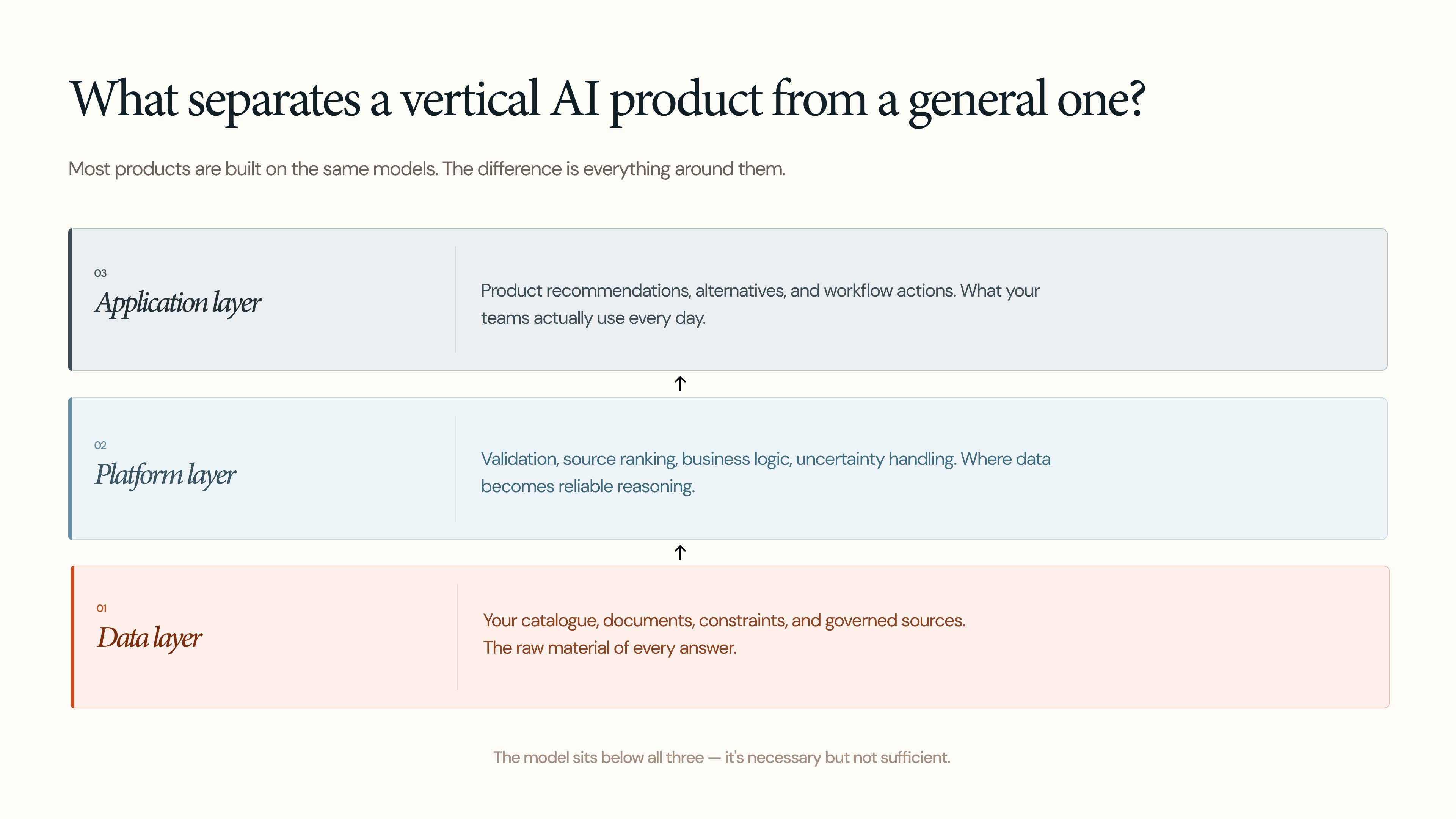
The real difference comes from the product built on top of the model. In a vertical AI product, I would look at three layers. The data layer covers what the system can access, but also the tools it has to work with that data and the constraints it has to respect. The platform layer is the control surface between the model and the user: access permissions, source ranking, validation, business logic, uncertainty handling, change management, and whether the system can bring an SME into the loop when confidence is low or the question crosses into expert judgment. The application layer is about whether the system understands the workflow it is entering and whether it can take vertical actions that matter in the real world, like surfacing approved alternatives, triggering a sample request, or routing a question into an internal approval process.
These are the layers that turn a product from sometimes impressive into consistently useful.
A strong model can still produce a stale answer
One of the easiest mistakes in AI product design is assuming correctness is static. A system can be working well on day one and quietly degrade simply because the data underneath it changes. A product may no longer be in the active portfolio, a source document may be outdated, internal guidance may have shifted, or the commercial team may now prefer a different recommendation path for strategic reasons. Regulatory interpretations can also move, and a product family can remain active while operating under new constraints that were never reflected in the system. In all of these cases, the model may still produce a clean answer and even cite a real source, but the answer is no longer grounded in the current reality of the business.
This is where change management becomes part of product quality. Reliability in technical selling depends on whether the system stays aligned with a moving business: portfolio changes, source governance, document freshness, evolving internal rules, and clear ownership over what should or should not be recommended. Without that layer, you do not have a dependable system. You have a fluent interface over drift.
Finding text is not the same as making a judgment
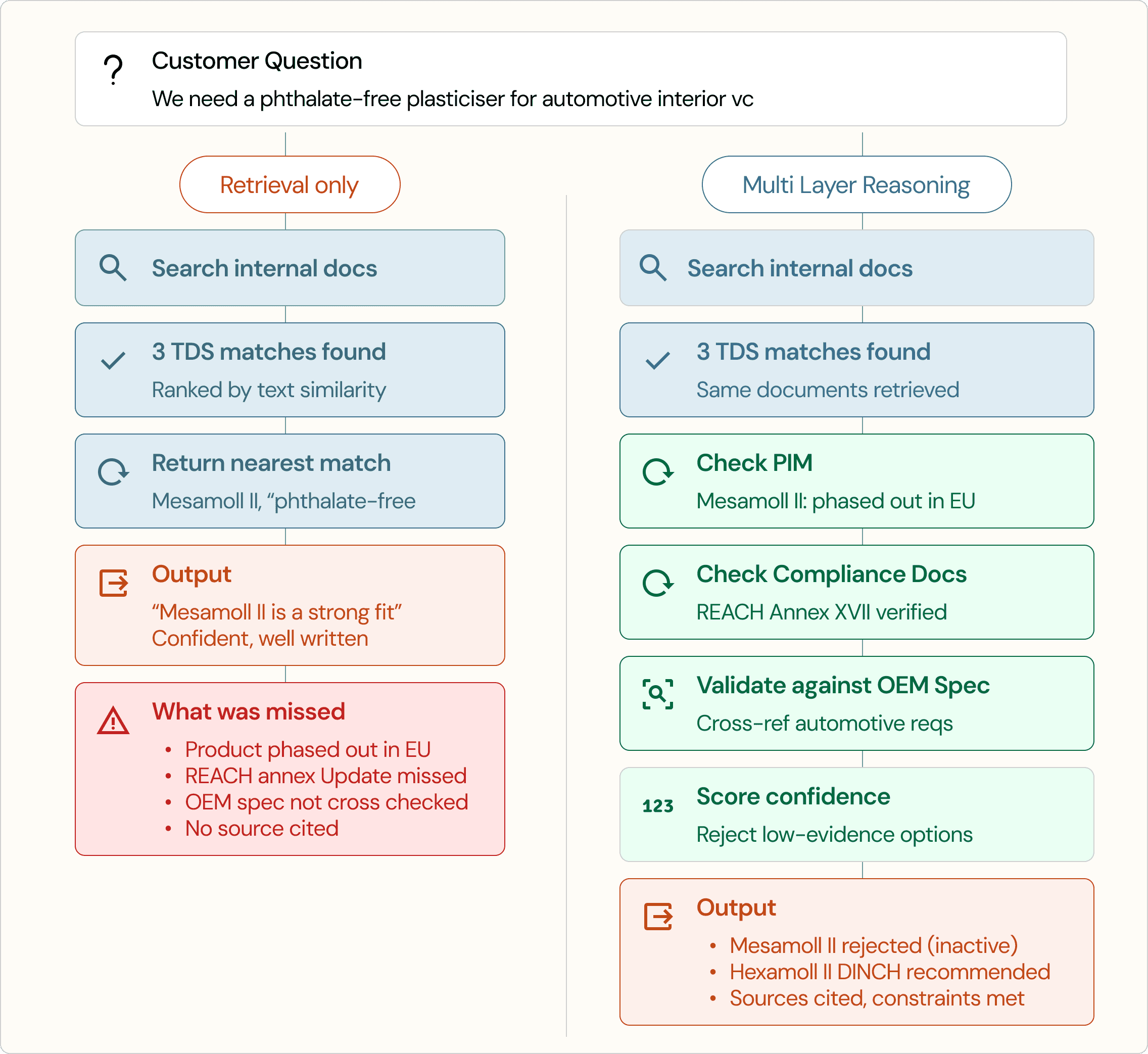
A common response to these failures is retrieval. The logic is reasonable: if the model lacks context, give it access to the right documents, let it search internal content, pull from data sheets and compliance files and product pages, and ground the answer in real source material. That absolutely helps, and any serious system should do it. But retrieval only solves part of the problem, because once the information is available, the harder question is how to judge it. Retrieval helps a system find information. It does not tell the system which facts are binding, which sources deserve the most weight, or whether the evidence is strong enough to support a recommendation at all.
Retrieval also scales less cleanly than people expect. As the data grows, results often get worse before they get better. This shows up clearly in alternatives and substitutions, where a generic system may retrieve something nearby and call it a match, while a domain expert would narrow the space differently, weigh different properties, and reject options that only look similar on the surface. That is the gap between access to information and actual judgment.
You’re asking the Model to do the work of a Product
Once you look past the demo, the failure modes are not that mysterious. The system misses constraints that were implied rather than stated, leans on stale data because freshness was never governed, or recommends something that looks technically adjacent but is no longer commercially relevant. In alternatives and substitutions, it often takes the shallow path, matching on visible similarity instead of reasoning the way a domain expert would.
These are not random glitches. They usually mean the workflow around the model is underbuilt. The model is being asked to do the work of a product data model, a business rules engine, and a source governance layer all at once. That can look surprisingly good in a short session, which is exactly why demo quality is such a poor proxy for production quality. The real test is whether the system holds up under messy, repetitive, high-consequence questions from the field, where shortcuts stop looking clever and start showing up as risk.
Building for production, not demos
A serious vertical system usually has a few things in common.
It has structured domain data instead of relying only on unstructured text.
It has recommendation logic that can reason within constraints rather than improvise over whatever documents were retrieved.
It has governed sources of truth, so not every document is treated as equally authoritative.
It has citation and refusal behaviour, so users can see why an answer was given and when the system knows it should stop.
It also fits the workflow people actually use. That sounds obvious, but it gets missed constantly. A rep does not need a system that generates a clever answer in isolation.
They need one that can help them move a real commercial process forward.
That may mean narrowing a product set, surfacing the missing variable that matters most, showing the governing source, or turning the recommendation into the next valid action in the workflow.
This is where vertical products earn their value.
Not by wrapping a chatbot around an industry, but by converting domain judgment into a system that can operate repeatedly and with control.
Build versus buy is really a question of what you are prepared to own
Companies often underestimate what it takes to build this internally. Model access is the easy part now, hence the abundance of failed internal demos.
Data modeling, taxonomy, source governance, validation logic, change management, feedback loops, evaluation infrastructure, and ongoing maintenance as both the business and the models change.
It’s a software at the end of the day, and software is like gardening, not construction. You do not build it once and walk away. You keep pruning, updating, and correcting for drift as the environment around it changes.
None of that means companies should never build.
But many organizations are not deciding between buying software and doing a lightweight internal prototype. They are deciding whether they want to own a living system that has to stay aligned with a changing catalogue, changing commercial priorities, and changing models.
The same applies when buying.
Buying does not remove the need for ownership. You still need data readiness, clear internal responsibility, and a real evaluation process.
The difference is whether you are taking on the full burden of building and maintaining the system yourself or choosing a product that already treats those layers as first-class problems.

Evaluation should happen on real field questions, not polished demos
The cleanest way to evaluate any solution is to stop asking whether it looks impressive and start asking whether it holds up on the questions that actually matter.
That means using real field questions, especially the messy ones, the multi-constraint ones, and the ones where the right answer may be uncertainty rather than confidence.
From there, the standard becomes much clearer.
Does the system give a correct answer, stay consistent, ground the answer in the right source, and behave honestly when the evidence is weak or incomplete?
That is a more demanding test than a polished demo, but it is also the only one that tells you whether the system is ready for production.
The category should be judged at that level. Not by how well the product talks, but by how reliably it helps someone make the next correct move.

The goal is speed with judgment
General-purpose AI already has real value in commercial work, and teams should use it where it helps. It saves time, reduces friction, and improves execution across a wide range of low-stakes tasks.
Technical selling is a different class of problem because the answer is not just informational. It influences recommendations, tradeoffs, and decisions that are constrained enough to matter and easy to get wrong in subtle ways.
Fluency on its own is not a useful standard here. What matters is whether the system can turn data, workflow, judgment, and trust into something repeatable. That is where product quality lives, and in technical selling, that is the bar.

